|
I am a Ph.D. student advised by Prof. Trevor Darrell at UC Berkeley. Previously, I graduated from Peking University with a B.S. degree in computer science. I build generalist vision and robotic models. Email / Google Scholar / Github / CV / WeChat |
|
{kind=link}
|
|
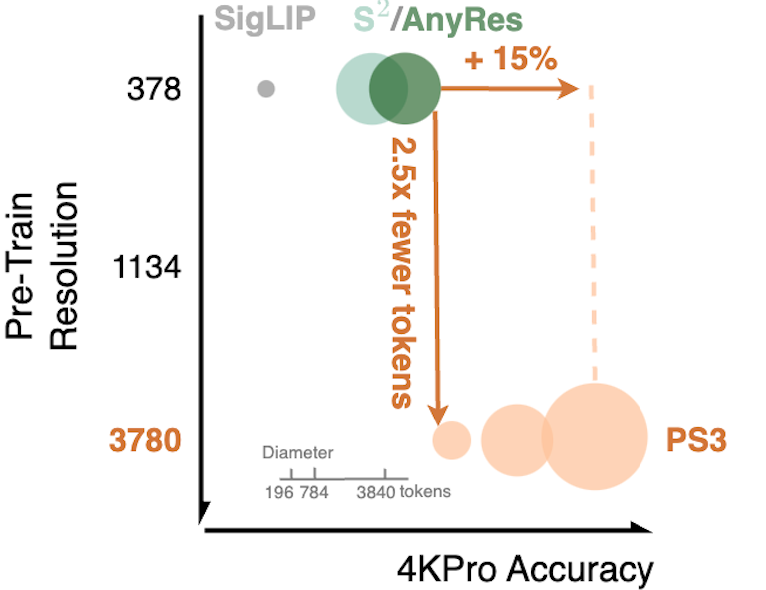 |
Baifeng Shi, Boyi Li, Han Cai, Yao Lu, Sifei Liu, Marco Pavone, Jan Kautz, Song Han, Trevor Darrell, Pavlo Molchanov, Hongxu (Danny) Yin, CVPR, 2025 abstract / website / pdf / code / Previous vision models such as SigLIP and DINOv2 are usually pre-trained at low resolutions (e.g., 384x384), limiting their performance of high-resolution perception. We propose PS3, a vision model that scales pre-training to 4K resolution with a near-constant cost. PS3 efficiently processes high-res images via top-down (i.e., prompt-aware) patch selection. We then introduce VILA-HD, a state-of-the-art high-res MLLM with PS3 as the vision encoder. VILA-HD achieves better performance and efficiency than previous models on various benchmarks including a 4K-res benchmark, 4KPro, that's introduced in this work. |
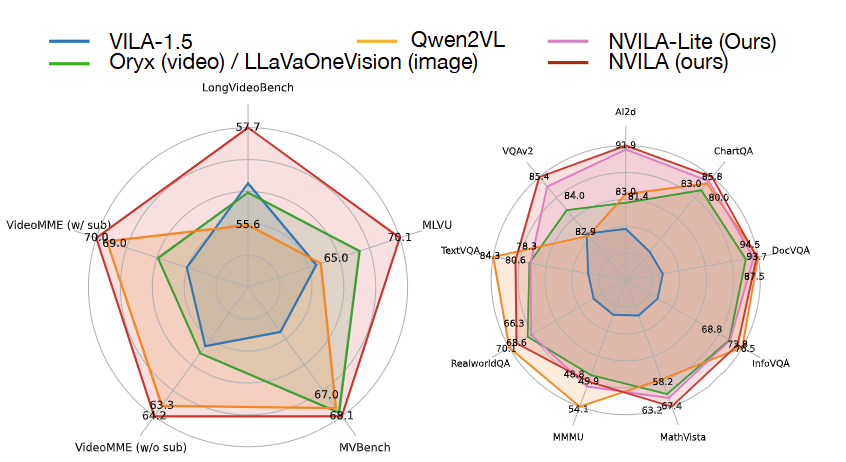 |
Zhijian Liu*, Ligeng Zhu*, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu (Danny) Yin^, Song Han^, Yao Lu*^ CVPR, 2025 abstract / website / demo / pdf / code / models NVILA is a family of open VLMs designed to optimize both efficiency and accuracy for efficient video understanding and multi-image understanding . Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5×, fine-tuning memory usage by 3.4×, pre-filling latency by 1.6-2.2×, and decoding latency by 1.2-2.8×. We make our code and models available to facilitate reproducibility. |
 |
Baifeng Shi, Ziyang Wu, Maolin Mao, Xin Wang, Trevor Darrell, ECCV, 2024 abstract / pdf / code / We find that smaller vision models (e.g., ViT-B or Vit-L) run on larger image scales are usually better than larger models (e.g., ViT-H, ViT-G) and can also learn similar representations as larger models. |

|
Baifeng Shi, Trevor Darrell, Xin Wang CVPR, 2023 website / abstract / pdf / code / 知乎 We build ViTs with the ability of top-down attention, i.e., steering its attention to specific objects when given a prompt. |
|
|
 |
Dantong Niu*, Yuvan Sharma*, Baifeng Shi*, Rachel Ding, Matteo Gioia, Haoru Xue, Henry Tsai, Konstantinos Kallidromitis, Anirudh Pai, Shankar S. Shastry, Trevor Darrell, Jitendra Malik Roei Herzig arXiv, 2025 abstract / pdf / website / We show that a grasping policy, trained on randomly constructed toys, can directly zero-shot generalize to real-world object grasping with 67%-80% success rates. We find that the key to this level of generalization lies in the object-centric visual representations. |
 |
Ilija Radosavovic, Bike Zhang, Baifeng Shi, Jathushan Rajasegaran, Sarthak Kamat, Trevor Darrell, Koushil Sreenath, Jitendra Malik NeurIPS, 2024 abstract / pdf / website / We formulate humanoid locomotion as a next token prediction problem. This enables learning to walk from in-the-wild data such as Youtube videos. |
 |
Ilija Radosavovic, Baifeng Shi, Letian Fu, Ken Goldberg, Trevor Darrell*, Jitendra Malik* CoRL, 2023 abstract / pdf / website / We make imitation learning easier by MAE pre-training on sensorimotor sequences. |
|
|
|
[Apr 2025] Scaling Vision Pre-Training to 4K Resolution, Boston University, hosted by Tianle Chen and Bryan Plummer [slides] [Apr 2025] Scaling Vision Pre-Training to 4K Resolution, Princeton University, hosted by Xindi Wu, Tyler Zhu, and Olga Russakovsky [slides] [Apr 2025] Scaling Vision Pre-Training to 4K Resolution, Google Deepmind, hosted by Tengda Han [Jun 2024] Scaling Up Visual Pre-Training: What’s Next?, AI Tea Talk Singapore, hosted by Kai Wang [Apr 2024] Scaling Up Visual Pre-Training: What’s Next?, VGG @ University of Oxford, hosted by Guanqi Zhan [slides] [Mar 2024] Scaling Up Visual Pre-Training: What’s Next?, Prof. Yi Ma's group @ UC Berkeley, hosted by Ziyang Wu [Oct 2023] Principles and Applications of Bottom-Up and Top-Down Visual Attention, Peking University, hosted by Yufei Ding [slides] [Jun 2023] Principles and Applications of Bottom-Up and Top-Down Visual Attention, TechBeat |
|
|